FastAPI Pagination Pt. IV: fastapi-pagination
Introduction
Welcome to the fourth and final installment of our series on pagination techniques in FastAPI. Over the course of this journey, we've explored various pagination strategies, starting with the foundational the limit/offset method in our first article, advancing to the page/per_page approach in the second, and delving into the complexities of cursor-based pagination in the third. Each method brought its own set of advantages and considerations, adapted to different use cases and data handling needs.
In this final article, we will turn our attention to a powerful tool designed to improve the implementation of pagination in FastAPI applications: the FastAPI Pagination library. This Python library offers a simplified but highly effective way to implement pagination into projects, abstracting away the complexity associated with manual pagination configuration and allowing developers to focus on ensuring optimal performance and user experience.
Implementation
Installation
At the beginning we have to install our library:
Copied!pip install fastapi-pagination
We will add our new endpoints to the existing main.py file, so that we have all endpoints related to pagination in one place and can easily compare them.
Page Number
Ensure that you have used endpoint /movie to populate the database before starting work on the new pagination method.
On line 5, we import Page, which is the class representing the paginated data for the Page Number Pagination method, and add_pagination adds pagination functionality to our FastAPI application.
The FastAPI Pagination library supports Databases (with one exception, but more on that later), which we used previously to communicate with our database. For this reason, we can import the corresponding function responsible for the pagination process itself in line 6.
In line 13 we add add_pagination to our application.
At line 168, we specify that we expect the Movie model to be paginated in Page format from the fastapi pagination library as the response.
The Page response by default contains 5 values within it. items for a list of paginated data, page as the numerical value of the current page, size as the number of results displayed per page (we called it per_page in part 2 of the tutorial) , pages as the total number of pages and total as the total number of all results.
The default value for page is 1 and size is 50, but this can be customized as we will show later.
In line 170 returns the result of a call of the paginate function, where the first argument is our database and the second is our query.
Copied!import json import sqlalchemy from fastapi import FastAPI, Query, Request from fastapi_pagination import Page, add_pagination from fastapi_pagination.ext.databases import paginate from database import database, movie_table from models import Movie, PaginatedResponse, PaginatedResponseC, PaginatedResponseP app = FastAPI() add_pagination(app) @app.get("/") def home(): return {"Hello": "World"} @app.post("/movies", response_model=dict, status_code=201) async def load_movies_to_database(): with open("movies_examples.json", "r") as f: data = json.load(f) await database.connect() for movie in data: query = movie_table.select().where(movie_table.c.id == movie["id"]) result = await database.fetch_one(query) if result is None: query = movie_table.insert().values(movie) await database.execute(query) await database.disconnect() return {"status": "Movies loaded successfully"} async def paginate_r( request: Request, limit: int, offset: int ) -> PaginatedResponse[Movie]: await database.connect() query = movie_table.select().limit(limit).offset(offset) movies = await database.fetch_all(query) count_query = sqlalchemy.select(sqlalchemy.func.count()).select_from(movie_table) total = await database.fetch_one(count_query) base_url = str(request.base_url) next_page = ( f"{base_url}movie?limit={limit}&offset={offset + limit}" if offset + limit < total[0] else None ) prev_page = ( f"{base_url}movie?limit={limit}&offset={max(0, offset - limit)}" if offset - limit >= 0 else None ) await database.disconnect() return { "limit": limit, "offset": offset, "totalItems": total[0], "nextPageUrl": next_page, "prevPageUrl": prev_page, "results": movies, } @app.get("/movie", response_model=PaginatedResponse[Movie], status_code=200) async def get_all_movies( request: Request, limit: int = Query(10, gt=0), offset: int = Query(0, ge=0), ): return await paginate_r(request, limit, offset) async def paginate_p( request: Request, page: int, per_page: int ) -> PaginatedResponseP[Movie]: offset = (page - 1) * per_page await database.connect() query = movie_table.select().limit(per_page).offset(offset) movies = await database.fetch_all(query) count_query = sqlalchemy.select(sqlalchemy.func.count()).select_from(movie_table) total = await database.fetch_one(count_query) base_url = str(request.base_url) next_page = ( f"{base_url}moviep?page={page + 1}&per_page={per_page}" if offset + per_page < total[0] else None ) prev_page = ( f"{base_url}moviep?page={page - 1}&per_page={per_page}" if page > 1 else None ) await database.disconnect() return { "page": page, "per_page": per_page, "totalItems": total[0], "nextPageUrl": next_page, "prevPageUrl": prev_page, "results": movies, } @app.get("/moviep", response_model=PaginatedResponseP[Movie], status_code=200) async def get_all_movies_p( request: Request, page: int = Query(1, gt=0), per_page: int = Query(10, gt=0), ): return await paginate_p(request, page, per_page) async def paginate_c( request: Request, cursor: str = None, limit: int = 10 ) -> PaginatedResponseC[Movie]: await database.connect() if cursor is not None: query = ( movie_table.select() .where(sqlalchemy.text(f"id > {cursor}")) .limit(limit + 1) ) else: query = movie_table.select().limit(limit + 1) movies = await database.fetch_all(query) # If we have more movies than max_results, we prepare a next cursor if len(movies) > limit: next_cursor = str(movies[-1].id) # Convert to string movies = movies[:-1] # We remove the last movie, as it is not part of this page else: next_cursor = None count_query = sqlalchemy.select(sqlalchemy.func.count()).select_from(movie_table) total = await database.fetch_one(count_query) await database.disconnect() base_url = str(request.base_url) next_page = ( f"{base_url}moviec?cursor={next_cursor}&limit={limit}" if next_cursor is not None else None ) return { "totalItems": total[0], "limit": limit, "nextCursor": next_cursor, "nextPageUrl": next_page, "results": movies, } @app.get("/moviec", response_model=PaginatedResponseC[Movie], status_code=200) async def get_all_movies_c( request: Request, cursor: str = Query(None), limit: int = Query(10, gt=0), ): return await paginate_c(request, cursor, limit) @app.get("/moviel-p", response_model=Page[Movie], status_code=200) async def get_all_movies_l(): return await paginate(database, movie_table.select())
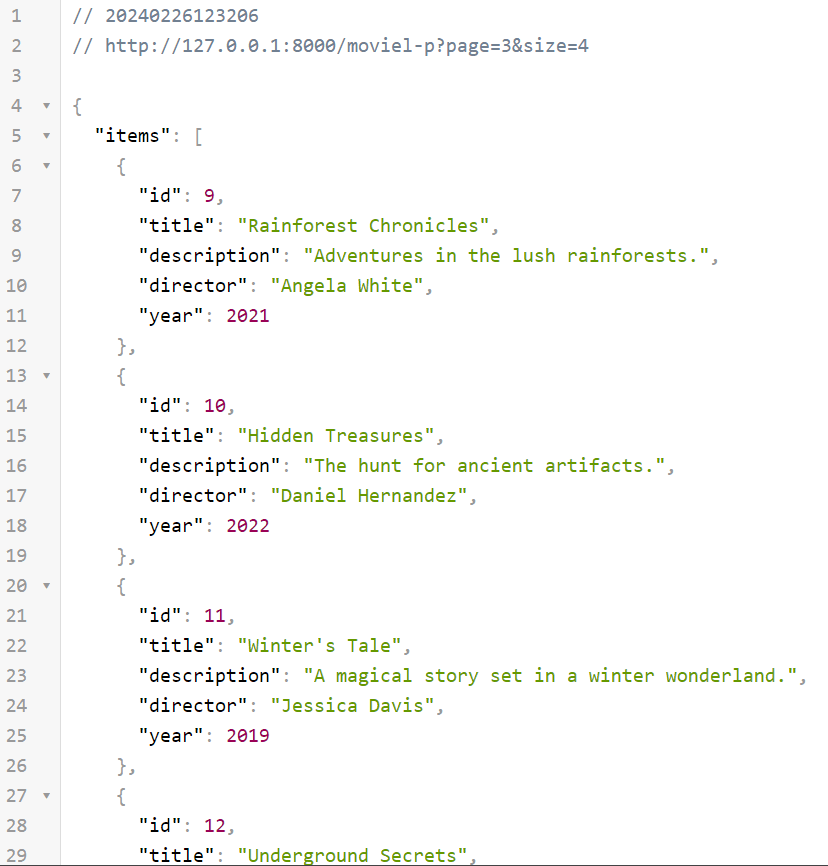
If we call our new endpoint /moviel-p?page=3&size=4 with the parameters page=3 and size=4, we will get the same results as using the endpoint created earlier in part 2nd of the tutorial /moviep?page=3&per_page=4.
Limit Offset Pagination
If we want to use limit/offset pagination as we did in the first part of our series, we need to import LimitOffsetPage as in line 169.
Then in line 172we add a new endpoint /moviel-l, where the results will be paginated by the limit/offset method, which is what the LimitOffsetPage model we imported above is responsible for.
The structure of the function itself remains unchanged. This allows us to have two different endpoints whose query results themselves are identical, but the way they are paginated is different, while not duplicating the same code and adhering to DRY principles.
The LimitOffsetPage response has 4 values. items for a list of paginated data, limit the number of results displayed per page, offset as the number of skipped results and total as the total number of all results.
The default value for offset is 0 and limit is 50, but they, like page and size on Page, can also be customized.
Copied!#... from fastapi_pagination import LimitOffsetPage, Page, add_pagination @app.get("/moviel-p", response_model=Page[Movie], status_code=200) @app.get("/moviel-l", response_model=LimitOffsetPage[Movie], status_code=200) async def get_all_movies_l(): return await paginate(database, movie_table.select())
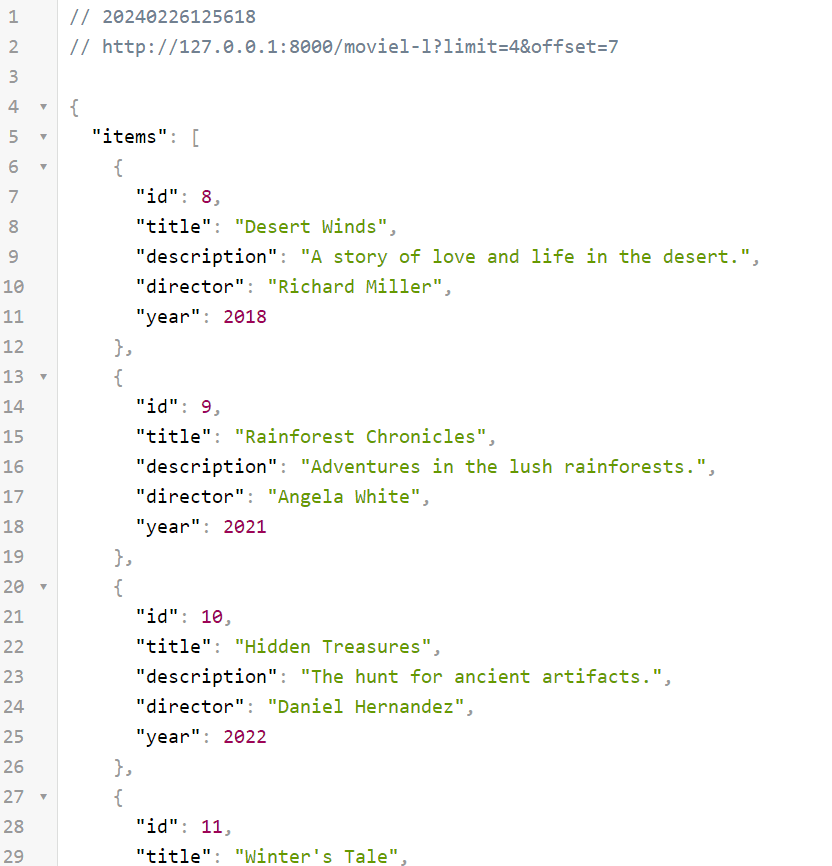
As in the previous scenario, when call the new endpoint /moviel-l?limit=4&offset=7 with the parameters limit=4 and offset=7, we will get the same results as with the created endpoint in the 1st part of the tutorial /movie?limit=4&offset=7.
Adding URLs
If we additionally want to receive URLs to the next or previous result pages in response to our query, we can do very simply. While in the previous parts of our tutorial we had to create a separate logic contained in a function for this, in the case of the fastapi-pagination library it is enough to import the Response Schema from fastapi_pagination.links module and use it as response_model.
Each Response Schema from the fastapi_pagination.links module contains an additional field called links, which contains the URLs to: first as the URL to the first page, last as the URL to the last page, self as the URL to the current page, next as the URL to the next page, prev as the URL to the previous page.
Copied!from fastapi_pagination.links import Page as PageLink from fastapi_pagination.links import LimitOffsetPage as LimitOffsetPageLink @app.get("/moviel-p", response_model=Page[Movie], status_code=200) @app.get("/moviel-pl", response_model=PageLink[Movie], status_code=200) @app.get("/moviel-l", response_model=LimitOffsetPage[Movie], status_code=200) @app.get("/moviel-ll", response_model=LimitOffsetPageLink[Movie], status_code=200) async def get_all_movies_l(): return await paginate(database, movie_table.select())
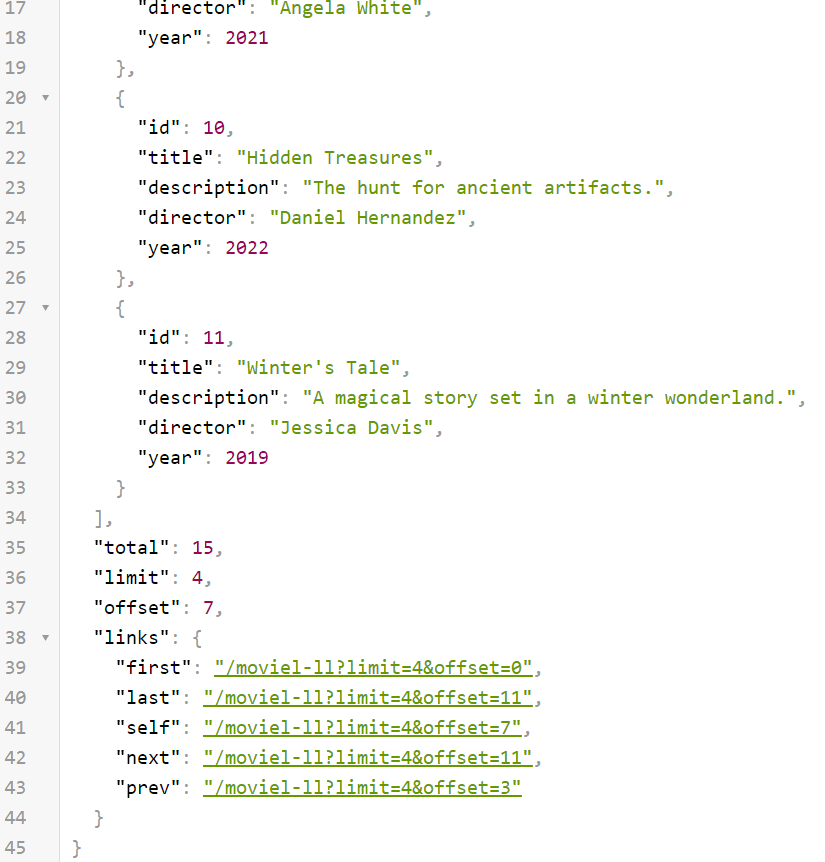
For example, if we call the endpoint /moviel-ll?limit=4&offset=7, which Response Schema LimitOffsetPage from the fastapi_pagination.links module, this is what our response will look like
Page customization
fastapi-pagination also offers the possibility to customize the queries used by the Response Schema.
In the example below, on line 169-171, we changed the default limit value in LimitOffsetPage to 10, the minimum value to 1 and the maximum value to 100.
Copied!#... LimitOffsetPage = LimitOffsetPage.with_custom_options( limit=Query(10, ge=1, le=100), ) @app.get("/moviel-p", response_model=Page[Movie], status_code=200) @app.get("/moviel-pl", response_model=PageLink[Movie], status_code=200) @app.get("/moviel-l", response_model=LimitOffsetPage[Movie], status_code=200) @app.get("/moviel-ll", response_model=LimitOffsetPageLink[Movie], status_code=200) async def get_all_movies_l(): return await paginate(database, movie_table.select())
Of course, fastapi-pagination provides much more extensive customization options. So if you want to customize (which I strongly recommend) entire pages or even pagination functions, you will find examples of this in the documentation.
Cursor Pagination
There is also an option in the fastapi-pagination library to use cursor-based pagination. However, it is only available for sqlalchemy and casandra backends. As we used the databases library in our tutorial, we need to make a few adjustments.
First we need to install two libraries:
Copied!pip install sqlalchemy sqlakeyset
Next, in database.py, we import sessionmaker from sqlalchemy.orm module [line 3] and create a session with the use of sqlalchemy [line 27].
Copied!import databases import sqlalchemy from sqlalchemy.orm import sessionmaker DATABASE_URL = "sqlite:///data.db" metadata = sqlalchemy.MetaData() movie_table = sqlalchemy.Table( "movies", metadata, sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True), sqlalchemy.Column("title", sqlalchemy.String), sqlalchemy.Column("description", sqlalchemy.String), sqlalchemy.Column("director", sqlalchemy.String), sqlalchemy.Column("year", sqlalchemy.Integer), ) engine = sqlalchemy.create_engine( DATABASE_URL, connect_args={"check_same_thread": False} ) metadata.create_all(engine) database = databases.Database(DATABASE_URL, force_rollback=False) SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
In our main.py, we need to import Depends from fastapi [line 4], CursorPage Response Schema from fastapi_pagination.cursor [line 6],paginate (we give it the alias paginateC because of a name conflict with paginate from fastapi_pagination.ext.databases) from fastapi_pagination.ext.sqlalchemy [line 8] and Session from sqlalchemy.orm [line 11].
In line 41 we create get_db function to manage the database session. By using it as a dependency, each request whose endpoint has it available will have a fresh database session available. Because the session is automatically managed and closed, we don't have to worry about manually opening and closing database connections, which increases code readability and application security.
Finally, in lines 192-194, we create the last endpoint /moviel-c that will handle cursor-based pagination. As response_model we use CursorPage Response Schema, that we imported at the top of the file. Into the get_users function we inject get_db function as a dependency to access the database session. Returning the value of the paginateC function call, we pass this particular session (db) as the first argument. As the second argument we give our query. But remember to contain the ordering. Otherwise a ValueError error will appear.
Copied!import json import sqlalchemy from fastapi import Depends, FastAPI, Query, Request from fastapi_pagination import LimitOffsetPage, Page, add_pagination from fastapi_pagination.cursor import CursorPage from fastapi_pagination.ext.databases import paginate from fastapi_pagination.ext.sqlalchemy import paginate as paginateC from fastapi_pagination.links import LimitOffsetPage as LimitOffsetPageLink from fastapi_pagination.links import Page as PageLink from sqlalchemy.orm import Session from database import SessionLocal, database, movie_table from models import Movie, PaginatedResponse, PaginatedResponseC, PaginatedResponseP app = FastAPI() add_pagination(app) @app.get("/") def home(): return {"Hello": "World"} @app.post("/movies", response_model=dict, status_code=201) async def load_movies_to_database(): with open("movies_examples.json", "r") as f: data = json.load(f) await database.connect() for movie in data: query = movie_table.select().where(movie_table.c.id == movie["id"]) result = await database.fetch_one(query) if result is None: query = movie_table.insert().values(movie) await database.execute(query) await database.disconnect() return {"status": "Movies loaded successfully"} def get_db(): db = SessionLocal() with db as session: yield session async def paginate_l( request: Request, limit: int, offset: int ) -> PaginatedResponse[Movie]: await database.connect() query = movie_table.select().limit(limit).offset(offset) movies = await database.fetch_all(query) count_query = sqlalchemy.select(sqlalchemy.func.count()).select_from(movie_table) total = await database.fetch_one(count_query) base_url = str(request.base_url) next_page = ( f"{base_url}movie?limit={limit}&offset={offset + limit}" if offset + limit < total[0] else None ) prev_page = ( f"{base_url}movie?limit={limit}&offset={max(0, offset - limit)}" if offset - limit >= 0 else None ) await database.disconnect() return { "limit": limit, "offset": offset, "totalItems": total[0], "nextPageUrl": next_page, "prevPageUrl": prev_page, "results": movies, } @app.get("/movie", response_model=PaginatedResponse[Movie], status_code=200) async def get_all_movies( request: Request, limit: int = Query(10, gt=0), offset: int = Query(0, ge=0), ): return await paginate_l(request, limit, offset) async def paginate_p( request: Request, page: int, per_page: int ) -> PaginatedResponseP[Movie]: offset = (page - 1) * per_page await database.connect() query = movie_table.select().limit(per_page).offset(offset) movies = await database.fetch_all(query) count_query = sqlalchemy.select(sqlalchemy.func.count()).select_from(movie_table) total = await database.fetch_one(count_query) base_url = str(request.base_url) next_page = ( f"{base_url}moviep?page={page + 1}&per_page={per_page}" if offset + per_page < total[0] else None ) prev_page = ( f"{base_url}moviep?page={page - 1}&per_page={per_page}" if page > 1 else None ) await database.disconnect() return { "page": page, "per_page": per_page, "totalItems": total[0], "nextPageUrl": next_page, "prevPageUrl": prev_page, "results": movies, } @app.get("/moviep", response_model=PaginatedResponseP[Movie], status_code=200) async def get_all_movies_p( request: Request, page: int = Query(1, gt=0), per_page: int = Query(10, gt=0), ): return await paginate_p(request, page, per_page) async def paginate_c( request: Request, cursor: str = None, limit: int = 10 ) -> PaginatedResponseC[Movie]: await database.connect() if cursor is not None: query = ( movie_table.select() .where(sqlalchemy.text(f"id > {cursor}")) .limit(limit + 1) ) else: query = movie_table.select().limit(limit + 1) movies = await database.fetch_all(query) # If we have more movies than max_results, we prepare a next cursor if len(movies) > limit: next_cursor = str(movies[-1].id) # Convert to string movies = movies[:-1] # We remove the last movie, as it is not part of this page else: next_cursor = None count_query = sqlalchemy.select(sqlalchemy.func.count()).select_from(movie_table) total = await database.fetch_one(count_query) await database.disconnect() base_url = str(request.base_url) next_page = ( f"{base_url}moviec?cursor={next_cursor}&limit={limit}" if next_cursor is not None else None ) return { "totalItems": total[0], "limit": limit, "nextCursor": next_cursor, "nextPageUrl": next_page, "results": movies, } @app.get("/moviec", response_model=PaginatedResponseC[Movie], status_code=200) async def get_all_movies_c( request: Request, cursor: str = Query(None), limit: int = Query(10, gt=0), ): return await paginate_c(request, cursor, limit) LimitOffsetPage = LimitOffsetPage.with_custom_options( limit=Query(10, ge=1, le=100), ) @app.get("/moviel-p", response_model=Page[Movie], status_code=200) @app.get("/moviel-pl", response_model=PageLink[Movie], status_code=200) @app.get("/moviel-l", response_model=LimitOffsetPage[Movie], status_code=200) @app.get("/moviel-ll", response_model=LimitOffsetPageLink[Movie], status_code=200) async def get_all_movies_l(): return await paginate(database, movie_table.select()) @app.get("/moviel-c", response_model=CursorPage[Movie]) async def get_users(db: Session = Depends(get_db)): return paginateC(db, sqlalchemy.select(movie_table).order_by(movie_table.c.id))
With our endpoint code already prepared, we can start testing it. Using Cursor Pagination in fastapi-pagination can be slightly tricky (which I had problems with myself).
First we have to call our endpoint with only Query the size like below:

Now we get the next_page field in the response, whose value we use as a cursor, as in the screenshot below:
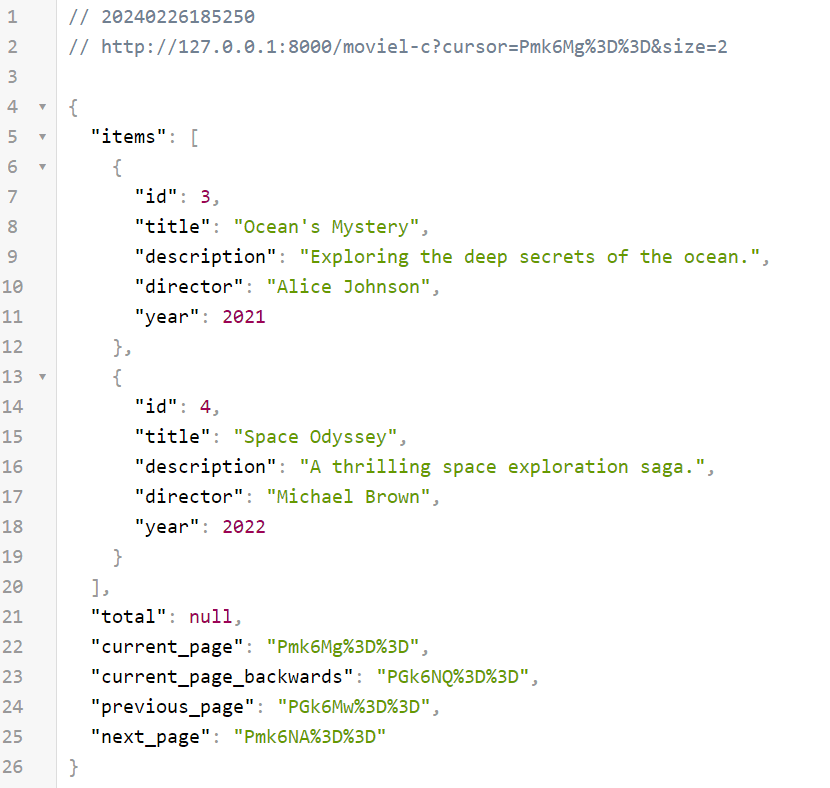
As far as I have noticed, the order of Query does not matter. So the endpoint could look just as well /moviel-c?cursor=Pmk6Mg%3D%3D&size=2 or /moviel-c?&size=2&cursor=Pmk6Mg%3D%3D and the effect would be the same. If we want to return to the previous page, we use the value from the previous_page field as the cursor.
Summary
The fourth and final part of our series on pagination in FastAPI introduces the fastapi-pagination library, a Python package designed to simplify the implementation of pagination in FastAPI applications. This library stands out for its simplicity of integration and its ability to abstract away the complexities associated with manual pagination configuration, providing developers with a streamlined and efficient approach to adding pagination to their projects.
One of the main advantages of using fastapi-pagination is the comprehensive support for various pagination strategies, including limit/offset, page/per_page and cursor-based methods. This versatility allows developers to adopt the most appropriate pagination technique for their specific use case without having to implement each strategy from scratch. Additionally, the library has been built to integrate seamlessly with FastAPI, ensuring that developers can utilize the full potential of FastAPI while maintaining clean and maintainable code.
However, while fastapi-pagination offers significant benefits in terms of simplicity and speed of development, it can also introduce some limitations. The abstraction of the library may limit customization options for developers who require more control over pagination logic or need to implement highly specialized pagination behavior (As we experienced when using the databases library, you would not be able to use cursor-based pagination. ). Furthermore, relying on a third-party library means that developers have to consider external dependencies, which can affect the long-term maintenance and scalability of their projects.
In summary, the fastapi-pagination library is a valuable tool for FastAPI developers who want to implement effective and efficient pagination with minimal effort. Its adoption can significantly improve the programmer's experience, although it is important to weigh its advantages against the need for customization and control in the specific context of the application.
Thank you for following our extensive series on pagination in FastAPI. We hope this recent article on the fastapi-pagination library has provided you with valuable information on improving your web applications with efficient pagination techniques. If you have any questions or would like to explore any of the aspects covered in this article in more depth, please contact via email. As always the whole code from the tutorial described here you can find in this repository.
Remember, taking care of yourself is as important as taking care of your code, so make sure to do both!