FastAPI Pagination Pt. III: Cursor
Introduction
Welcome to the third installment of our series on pagination techniques in FastAPI. Having explored the fundamentals of pagination with the limit/offset strategy in our first article, and delved into the page/per_page method in the second, we now turn our attention to a more advanced and efficient approach: cursor-based pagination.
Cursor-based pagination represents a significant evolution in how data is efficiently retrieved and navigated in web applications. Unlike the previous strategies that rely on numerical offsets or page numbers, cursor-based pagination uses a pointer (the "cursor") to manage and access data. This method offers several advantages, especially in terms of performance and user experience, making it particularly suitable for real-time data feeds and applications with large, continuously growing datasets.
In this article, we will explore the rules behind cursor-based pagination, how it compares to limit/offset and page/per_page methods, and why it may be the best choice for certain types of applications. We will provide detailed instructions for implementing cursor-based pagination in FastAPI, including code examples and best practices to ensure that the API can handle retrieval in the most efficient way possible.
Whether you're building a social media platform, a news aggregator or any application that requires smooth and scalable data navigation, understanding cursor-based pagination can significantly improve the way you manage and present your data. Join us to dive into the complexities of this powerful pagination technique and learn how to implement it in your FastAPI projects.
This function will return a list of movies starting from the movie with an id greater than the cursor, and a new cursor for the next page. If there are no more movies, the cursor and the nextPageUrl will be None.
Please note that this assumes that your Movie model has an id field that is a unique, sortable field (like a timestamp or an auto-incrementing id). If that's not the case, you'll need to adjust the query to use a different field.
In cursor-based pagination, it's common to only provide a "next" link and not a "previous" link. This is because the cursor points to a specific spot in the database, and getting the previous page would require knowing the cursor for the start of the previous page, which isn't typically stored.
Cursor strategy
Implementation
Before we start on the journey of implementing cursor-based pagination in FastAPI, it's important to make sure the basics are solid. If you are just joining us in this series, I strongly recommend that you revisit the first part of our guide, where we detailed steps for setting up your development environment, preparing your database and the basics of pagination using the limit/offset strategy.
After configuration, our second article dig deeper into the page/per_page pagination method, providing an overview of a user-friendly approach to navigating large datasets. Understanding the page/per_page strategy is useful as it allows you to appreciate the advantages and scenarios where cursor-based pagination may be a more efficient alternative.
Moving on to the specifics of cursor-based pagination, it is important to note that this method offers a dynamic way of viewing datasets, especially those that are frequently updated or whose total size is not known in advance. Cursor-based pagination uses a cursor to track positions in the dataset, allowing for a smoother fetching of data without the overhead associated with traditional offset-based methods.
For clarity and ease of understanding, we will continue to work with the same files and data introduced in the first part of the series, which were then extended in the second article with an exploration of the page/per_page method. By maintaining a consistent environment and dataset, we aim to simplify the learning process and make it easier to directly compare different pagination strategies.
Ensure that you have used endpoint http://127.0.0.1:8000/movie to populate the database before starting work on the new pagination method.
Preparing Pydantic model
As we did in the previous two parts, we will now use the previous Pydantic model models and adapt them to the cursor-based pagination method.
A key difference in the PaginatedResponseC model is the use of the nextCursor field instead of relying on numeric offsets (offset) or explicit page numbers (page). The cursor represents a pointer to a specific location in the dataset, allowing the pagination mechanism to retrieve the next set of results based on this dynamic reference point. This approach is inherently more suitable for cursor-based pagination strategies for several reasons.
Cursors provide a stateless way of viewing data that is more efficient than calculating offsets, especially for large data sets. By pointing directly to the next piece of data, cursors eliminate the need for the server to recalculate the offset for each request, reducing computational overhead and improving response times.
In scenarios where the dataset is frequently updated (with new records added or existing records deleted), cursor-based pagination ensures that users do not miss or see duplicate records when navigating through pages. This is a common problem with offset-based pagination, where moving data can affect the integrity of paginated results.
The included nextCursor field in addition to the nextPageUrl, which contains this cursor, simplifies client-side data retrieval logic. Clients no longer need to calculate the next offset or page number; instead, they can use the provided cursor or URL to seamlessly access the next data.
Copied!from typing import Generic, List, Optional, TypeVar from pydantic import AnyHttpUrl, BaseModel, Field T = TypeVar("T") class Movie(BaseModel): id: int title: str description: str director: str year: int class PaginatedResponse(BaseModel, Generic[T]): limit: int = Field(description="Number of items returned in the response") offset: int = Field(description="Index of the first item returned in the response") totalItems: int = Field(description="Total number of items in the database") nextPageUrl: Optional[AnyHttpUrl] = None Field(description="URL to the next page of results if available, otherwise null") prevPageUrl: Optional[AnyHttpUrl] = None Field( description="URL to the previous page of results if available, otherwise null" ) results: List[T] = Field( description="List of items returned in response according to the provided parameters" ) class PaginatedResponseP(BaseModel, Generic[T]): page: int = Field(description="The current page number being displayed") per_page: int = Field(description="The number of items displayed on each page") totalItems: int = Field(description="Total number of items in the database") nextPageUrl: Optional[AnyHttpUrl] = None Field(description="URL to the next page of results if available, otherwise null") prevPageUrl: Optional[AnyHttpUrl] = None Field( description="URL to the previous page of results if available, otherwise null" ) results: List[T] = Field( description="List of items returned in response according to the provided parameters" ) class PaginatedResponseC(BaseModel, Generic[T]): totalItems: int = Field(description="Total number of items in the database") limit: int = Field(description="Number of items returned in the response") nextCursor: Optional[str] = None Field(description="Cursor for the next page of results") nextPageUrl: Optional[AnyHttpUrl] = None Field(description="URL to the next page of results if available, otherwise null") results: List[T] = Field( description="List of items returned in response according to the provided parameters" )
Creating Endpoint
Cursor-based pagination uses a cursor to navigate through the dataset. This cursor, often a unique identifier or timestamp, serves as a reference point for retrieving subsequent data sets. Unlike traditional pagination, which relies on numerical offsets or explicit page numbers, cursor-based pagination provides a smooth and consistent flow of data, especially in dynamic environments where datasets change frequently.
In this example to implementing cursor-based pagination in FastAPI, we decided to use a database record id as a cursor. This decision is based on the inherent characteristics of the id: it is a unique, sequential identifier that naturally lends itself to being an effective cursor. Note, however, that the cursor can be any value that provides a consistent and predictable sequence of records. Examples of alternative cursor values include timestamps for records that are frequently updated or added, a unique hash generated from the contents of a record, or even a combination of fields that can guarantee a unique and sequential data flow.
The paginate_c function in our FastAPI application demonstrates the practical use of an id as a cursor. When a request is sent to retrieve a set of records, the function checks whether a cursor value (in this case id) is provided. If present, the query is constructed to select records where the id is greater than the cursor value, ensuring that the returned dataset starts immediately after the last record received by the client. This method elegantly solves the need for pagination in datasets that are large or frequently updated, as it allows queries to be sent efficiently and directly without recalculating offsets.
Furthermore, this function is designed to fetch one record more than the limit set by the client. This extra record is a smart mechanism to determine if there is a next page of data. If the number of records retrieved exceeds the limit, this means that more data is available and the identifier of the extra record is used as a cursor for the next page. The function then truncates this additional record from the response sent back to the client, ensuring that the size of the response is within the requested limit.
This cursor-based approach, with id as the cursor, offers a scalable and user-friendly method of navigating through the data. However, depending on the specific requirements of the application and its data, other cursor strategies may be more appropriate. For example, a timestamp cursor may be ideal for a news application where articles are retrieved based on their publication date, ensuring that the most recent articles are retrieved first. Alternatively, a unique hash may be appropriate for datasets where records are not inherently sequential, but can be ordered based on the hash of their contents.
In cursor-based pagination, URLs to previous pages are usually not provided due to the method's emphasis on forward navigation, statelessness and simplicity. This design choice is consistent with cursor-based pagination use cases such as social media feeds or real-time data streams, where the emphasis is on efficient access to newer elements. The inclusion of backward navigation complicates the pagination logic and can impact performance, especially for large or frequently updated datasets. Furthermore, in dynamic datasets, the concept of 'previous page' can be confusing as data can change, leading to a potentially confusing user experience. Cursor-based pagination is optimized for scenarios where users primarily engage with the most recent or next data set, making the backtracking mechanism less critical.
Copied!import json import sqlalchemy from fastapi import FastAPI, Query, Request from database import database, movie_table from models import Movie, PaginatedResponse, PaginatedResponseC, PaginatedResponseP app = FastAPI() @app.get("/") def home(): return {"Hello": "World"} @app.post("/movies", response_model=dict, status_code=201) async def load_movies_to_database(): with open("movies_examples.json", "r") as f: data = json.load(f) await database.connect() for movie in data: query = movie_table.select().where(movie_table.c.id == movie["id"]) result = await database.fetch_one(query) if result is None: query = movie_table.insert().values(movie) await database.execute(query) await database.disconnect() return {"status": "Movies loaded successfully"} async def paginate_l( request: Request, limit: int, offset: int ) -> PaginatedResponse[Movie]: await database.connect() query = movie_table.select().limit(limit).offset(offset) movies = await database.fetch_all(query) count_query = sqlalchemy.select(sqlalchemy.func.count()).select_from(movie_table) total = await database.fetch_one(count_query) base_url = str(request.base_url) next_page = ( f"{base_url}movie?limit={limit}&offset={offset + limit}" if offset + limit < total[0] else None ) prev_page = ( f"{base_url}movie?limit={limit}&offset={max(0, offset - limit)}" if offset - limit >= 0 else None ) await database.disconnect() return { "limit": limit, "offset": offset, "totalItems": total[0], "nextPageUrl": next_page, "prevPageUrl": prev_page, "results": movies, } @app.get("/movie", response_model=PaginatedResponse[Movie], status_code=200) async def get_all_movies( request: Request, limit: int = Query(10, gt=0), offset: int = Query(0, ge=0), ): return await paginate_l(request, limit, offset) async def paginate_p( request: Request, page: int, per_page: int ) -> PaginatedResponseP[Movie]: offset = (page - 1) * per_page await database.connect() query = movie_table.select().limit(per_page).offset(offset) movies = await database.fetch_all(query) count_query = sqlalchemy.select(sqlalchemy.func.count()).select_from(movie_table) total = await database.fetch_one(count_query) base_url = str(request.base_url) next_page = ( f"{base_url}moviep?page={page + 1}&per_page={per_page}" if offset + per_page < total[0] else None ) prev_page = ( f"{base_url}moviep?page={page - 1}&per_page={per_page}" if page > 1 else None ) await database.disconnect() return { "page": page, "per_page": per_page, "totalItems": total[0], "nextPageUrl": next_page, "prevPageUrl": prev_page, "results": movies, } @app.get("/moviep", response_model=PaginatedResponseP[Movie], status_code=200) async def get_all_movies_p( request: Request, page: int = Query(1, gt=0), per_page: int = Query(10, gt=0), ): return await paginate_p(request, page, per_page) async def paginate_c( request: Request, cursor: str = None, limit: int = 10 ) -> PaginatedResponseC[Movie]: await database.connect() if cursor is not None: query = ( movie_table.select() .where(sqlalchemy.text(f"id > {cursor}")) .limit(limit + 1) ) else: query = movie_table.select().limit(limit + 1) movies = await database.fetch_all(query) # If we have more movies than max_results, we prepare a next cursor if len(movies) > limit: next_cursor = str(movies[-1].id) # Convert to string movies = movies[:-1] # We remove the last movie, as it is not part of this page else: next_cursor = None count_query = sqlalchemy.select(sqlalchemy.func.count()).select_from(movie_table) total = await database.fetch_one(count_query) await database.disconnect() base_url = str(request.base_url) next_page = ( f"{base_url}moviec?cursor={next_cursor}&limit={limit}" if next_cursor is not None else None ) return { "totalItems": total[0], "limit": limit, "nextCursor": next_cursor, "nextPageUrl": next_page, "results": movies, } @app.get("/moviec", response_model=PaginatedResponseC[Movie], status_code=200) async def get_all_movies_c( request: Request, cursor: str = Query(None), limit: int = Query(10, gt=0), ): return await paginate_c(request, cursor, limit)
Now that we have our new endpoint implementing cursor-based pagination we can try it out.
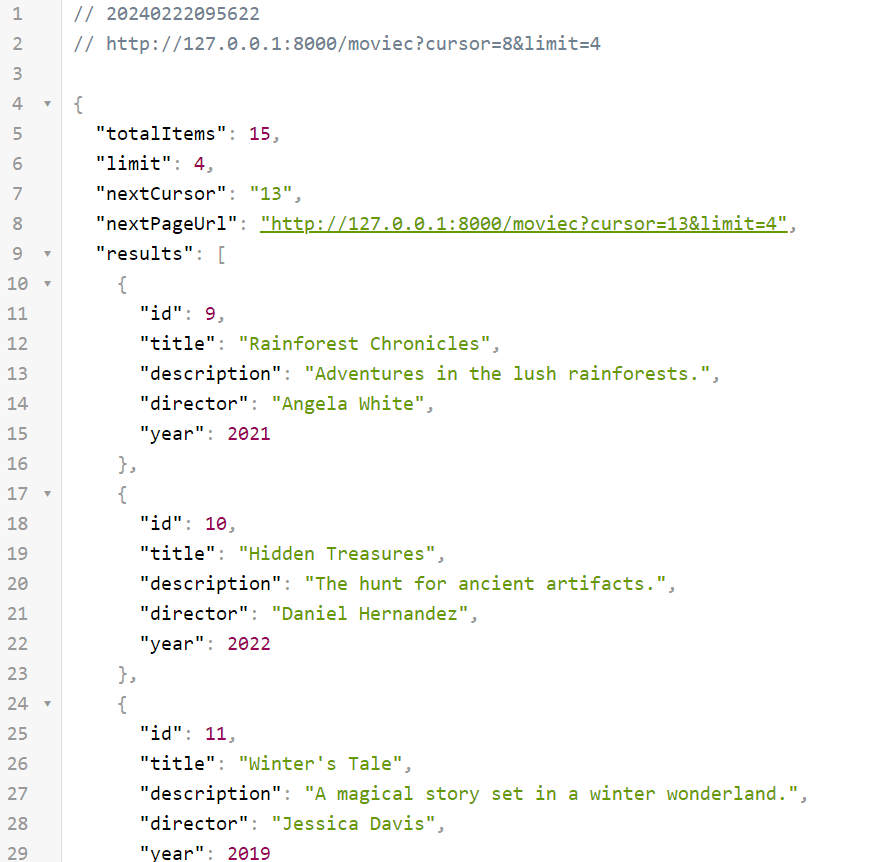
By setting the cursor id equal to 8, limiting the number of query max_results to 4 and using our endpoint (http://127.0.0.1:8000/moviec?cursor=8&limit=4), we get a response that is very similar to that for the page/per_page method from the previous part of the tutorial (where page=3 and per_page=4). However, we can see the differences between these methods to get a similar result.
Summary
The cursor-based pagination offers a sophisticated approach to data navigation, particularly preferred in scenarios requiring real-time updates or handling large, dynamic data sets. The strategy benefits from performance and user experience, enabling smooth forward navigation without the need to recalculate offsets, making it particularly suitable for applications such as social media feeds or live streams where the latest data is prioritized. Compared to limit/offset and page/per_page strategies, cursor-based pagination stands out for its ability to maintain a consistent view of data in rapidly changing environments, ensuring users don't encounter duplicates or miss entries as new data is added.
However, this method has its weaknesses. The main limitation is the inherent forward navigation design, which can make backward movement more complex and less intuitive than traditional pagination methods. This may not suit applications where users often need to navigate back and forth in a dataset. In addition, implementing cursor-based pagination requires a carefully designed database schema and query logic to use cursors effectively, which can increase programming complexity compared to simpler limit/offset or page/per_page methods.
In summary, while cursor-based pagination offers significant performance and user experience benefits for specific use cases, it requires careful consideration of the application's navigation needs and data structure. Its choice should depend on the nature of the dataset and typical user interactions in the application.
Thank you for taking the time to read through our exploration of cursor-based pagination in FastAPI. If you have any questions or would like to explore any of the aspects covered in this article in more depth, please contact via email. Stay tuned for the upcoming and final article in our pagination series. The whole code from the tutorial described here you can find in this repository.
Remember, taking care of yourself is as important as taking care of your code, so make sure to do both!