FastAPI Pagination Pt. II: Page/Per_page

Introduction
In the first part of our series, we explored the basics of pagination in
FastAPI, focusing on the limit/offset strategy - a key technique for managing
large datasets in scalable and efficient web applications. This method makes it
easier for the user to navigate large datasets by delivering content in smaller,
more manageable segments, reducing server load and increasing application
performance. Moving forward, in the second part we will focus on an alternative
approach: the page/per_page method.
The page/per_page method allows users to specify precisely the page of data
they want to access and the number of records displayed on each page. This level
of detail not only increases user independence in terms of the content viewed,
but also promotes more efficient use of server resources. In this article, we
will dive into the implementation of this method in FastAPI, with the aim of
achieving smooth and efficient pagination of data.
Page/per_page strategy
Implementation
Before going into the details of implementing the page/per_page method for
pagination in FastAPI, it's important to have a solid foundation. If you haven't
already done so, I highly recommend revisiting
the first part of our tutorial series.
There we detailed the initial steps necessary to set up your development
environment and database. This foundation is essential as it provides the right
infrastructure and understanding to successfully apply the pagination techniques
we are about to explore.
In the following sections, we will take you through the process of configuring
FastAPI endpoints to support page/per_page pagination. This will include
customizing the API logic to handle page number and size parameters, integrating
this functionality with database queries, and ensuring that the application can
dynamically adapt to different user requests. By following these steps, you will
be able to implement a solid pagination system that improves data management and
user satisfaction.
For the purposes of simplicity and transparency, we will continue to work with
the same files and data sets introduced in the first part of our guide. This
decision ensures a smooth integration of the new pagination strategies without
having to configure additional components or modify the existing infrastructure.
Building on the foundations we have already created, we can directly focus on
the implementation of the page/per_page method, adding new endpoints to our
FastAPI application.
This approach not only simplifies the development process, but also makes it
easier to directly compare the limit/offset strategy discussed earlier with
the page/per_page method we intend to explore. Maintaining a consistent
context allows us to clearly highlight the advantages and considerations of each
pagination strategy in the same application environment.
Ensure that you have used endpoint http://127.0.0.1:8000/movie to populate the
database before starting work on the new pagination method.
Preparing Pydantic model
In our tutorial today, we used the Pydantic model that was used for the
limit/offset strategy and will adapt it to page/per_page.
The addition of the PaginatedResponseP class marks an evolution towards a
page/per_page pagination approach. Like its precursor, this model contains
fields in line with the requirements of the pagination strategy: page,
per_page, totalItems, nextPageUrl, prevPageUrl and a general results
list. Unlike limit/offset pagination, the page field specifies the current
page number and the per_page defines the number of items to display on a
page, providing a user-friendly data navigation mechanism that allows users to
request specific pages directly.
Both paginated response models use the Field Pydantic feature to describe
fields, increasing the understandability of the API data structures for
developers. The inclusion of the Generic[T] type in these models highlights
their universality, allowing the pagination structure to be applied to a variety
of data types, therefore increasing the reusability and flexibility of the API
to adapt to different entities. This design choice highlights a thoughtful
approach to API development, prioritizing adaptability and developer experience.
Copied!from typing import Generic, List, Optional, TypeVar from pydantic import AnyHttpUrl, BaseModel, Field T = TypeVar("T") class Movie(BaseModel): id: int title: str description: str director: str year: int class PaginatedResponse(BaseModel, Generic[T]): limit: int = Field(description="Number of items returned in the response") offset: int = Field(description="Index of the first item returned in the response") totalItems: int = Field(description="Total number of items in the database") nextPageUrl: Optional[AnyHttpUrl] = None Field(description="URL to the next page of results if available, otherwise null") prevPageUrl: Optional[AnyHttpUrl] = None Field( description="URL to the previous page of results if available, otherwise null" ) results: List[T] = Field( description="List of items returned in response according to the provided parameters" ) class PaginatedResponseP(BaseModel, Generic[T]): page: int = Field(description="The current page number being displayed") per_page: int = Field(description="The number of items displayed on each page") totalItems: int = Field(description="Total number of items in the database") nextPageUrl: Optional[AnyHttpUrl] = None Field(description="URL to the next page of results if available, otherwise null") prevPageUrl: Optional[AnyHttpUrl] = None Field( description="URL to the previous page of results if available, otherwise null" ) results: List[T] = Field( description="List of items returned in response according to the provided parameters" )
Creating Endpoint
The core of the update is the addition of an asynchronous utility function,
paginate_p, designed to simplify pagination based on page numbers and elements
per page rather than offset and limit parameters. This function calculates an
offset based on the given page number and per_page value, sends a query to
the database to retrieve the relevant piece of video data and dynamically
generates URLs for navigation to the next and previous page based on the current
page and per_page settings. Including the total number of elements in the
response helps to understand the scope of the data and plan navigation.
The get_all_movies_p endpoint then uses this paginate_p function to offer an
API route to access paginated movie data. Users can specify the page number and
the desired number of items per page via query parameters, making the retrieval
more intuitive and responsive. This method simplifies the process of navigating
large datasets by allowing direct access to specific pages and adjusting the
amount of data returned in each request.
Copied!import json import sqlalchemy from fastapi import FastAPI, Query, Request from database import database, movie_table from models import Movie, PaginatedResponse, PaginatedResponseP app = FastAPI() @app.get("/") def home(): return {"Hello": "World"} @app.post("/movies", response_model=dict, status_code=201) async def load_movies_to_database(): with open("movies_examples.json", "r") as f: data = json.load(f) await database.connect() for movie in data: query = movie_table.select().where(movie_table.c.id == movie["id"]) result = await database.fetch_one(query) if result is None: query = movie_table.insert().values(movie) await database.execute(query) await database.disconnect() return {"status": "Movies loaded successfully"} async def paginate_l( request: Request, limit: int, offset: int ) -> PaginatedResponse[Movie]: await database.connect() query = movie_table.select().limit(limit).offset(offset) movies = await database.fetch_all(query) count_query = sqlalchemy.select(sqlalchemy.func.count()).select_from(movie_table) total = await database.fetch_one(count_query) base_url = str(request.base_url) next_page = ( f"{base_url}movie?limit={limit}&offset={offset + limit}" if offset + limit < total[0] else None ) prev_page = ( f"{base_url}movie?limit={limit}&offset={max(0, offset - limit)}" if offset - limit >= 0 else None ) await database.disconnect() return { "limit": limit, "offset": offset, "totalItems": total[0], "nextPageUrl": next_page, "prevPageUrl": prev_page, "results": movies, } @app.get("/movie", response_model=PaginatedResponse[Movie], status_code=200) async def get_all_movies( request: Request, limit: int = Query(10, gt=0), offset: int = Query(0, ge=0), ): return await paginate_l(request, limit, offset) async def paginate_p( request: Request, page: int, per_page: int ) -> PaginatedResponseP[Movie]: offset = (page - 1) * per_page await database.connect() query = movie_table.select().limit(per_page).offset(offset) movies = await database.fetch_all(query) count_query = sqlalchemy.select(sqlalchemy.func.count()).select_from(movie_table) total = await database.fetch_one(count_query) base_url = str(request.base_url) next_page = ( f"{base_url}moviep?page={page + 1}&per_page={per_page}" if offset + per_page < total[0] else None ) prev_page = ( f"{base_url}moviep?page={page - 1}&per_page={per_page}" if page > 1 else None ) await database.disconnect() return { "page": page, "per_page": per_page, "totalItems": total[0], "nextPageUrl": next_page, "prevPageUrl": prev_page, "results": movies, } @app.get("/moviep", response_model=PaginatedResponseP[Movie], status_code=200) async def get_all_movies_p( request: Request, page: int = Query(1, gt=0), per_page: int = Query(10, gt=0), ): return await paginate_p(request, page, per_page)
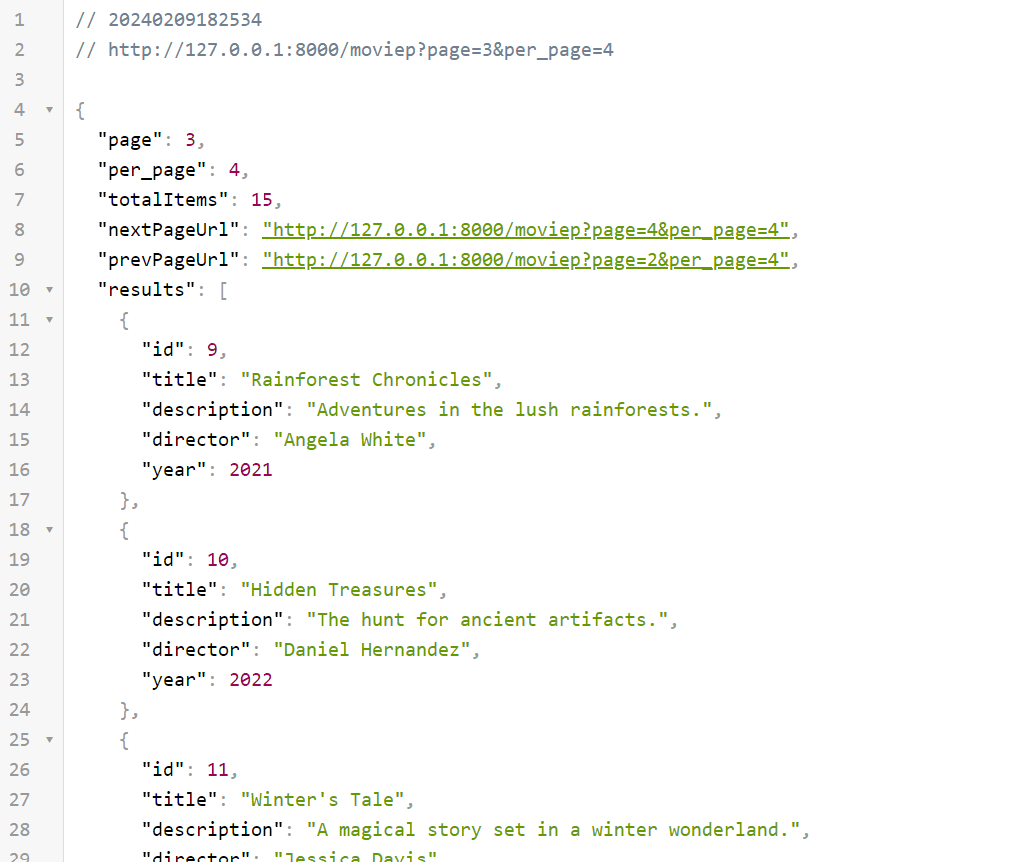
Now when we use our new endpoint with query params such as page equal to 3 and
per_page equal to 4 (http://127.0.0.1:8000/moviep?page=3&per_page=4), the
response should be similar to the one on the screen below:
Summary
Pagination using FastAPI's page/per_page strategy offers an intuitive and
simple method for users to navigate large datasets. This approach allows users
to directly specify which page of data they want to access and the number of
elements to be displayed on each page, making it particularly suitable for
applications where the concept of 'pages' is integral to the user experience,
such as content management systems, e-commerce platforms or social media
channels.
One of the main advantages of this strategy is its intuitive nature, which allows users to easily understand and navigate the data. Each page has a consistent number of elements, which increases predictability and user satisfaction. Additionally, the simplicity of specifying page numbers and sizes in the query parameters eliminates the need to manually calculate offsets, simplifying the creation and use of API endpoints.
However, the page/per_page strategy is not without disadvantages, especially
when compared to the limit/offset approach. Performance issues can appear in
the case of very large datasets, as it can be more computationally intensive to
calculate the starting point for data searches on high page numbers. This
problem comes from the need to count records in the database to determine page
offsets, which may not be as simple as using a simple offset. Furthermore, this
pagination method offers less flexibility to retrieve specific ranges of data
that do not conform to predefined page boundaries. Users who wish to access a
custom slice of data may find the limit/offset method more appropriate.
Finally, in environments where the dataset is highly dynamic with frequent
additions or deletions, page-based navigation may lead to inconsistencies such
as potentially missing or encountering duplicate elements as the composition of
pages changes over time.
In general, while the page/per_page pagination strategy improves user
experience by providing an easy-to-navigate and predictable presentation of the
data, it encounters limitations in terms of performance for large datasets and
flexibility in data retrieval. The choice between page/per_page and
limit/offset strategies should be determined by the specific needs of the
application, taking into account factors such as the size of the dataset, the
design of the user interface and the dynamic nature of the data.
Thank you for taking the time to read this article on implementing page/per_page pagination strategies in FastAPI. We hope it has provided you with valuable insights and practical knowledge to improve the user experience and performance of your web applications.
If you have any questions or would like further explanation on any of the topics we have covered, please do not hesitate to contact us via email. We are always happy to help and engage in discussions to help enrich understanding and support the sharing of knowledge by the community. Additionally, stay tuned for the upcoming third article in our pagination series. The whole code from the tutorial described here can be found in this repository.
Remember, taking care of yourself is as important as taking care of your code, so make sure to do both!