FastAPI Pagination Pt. I: Limit/Offset

In the dynamic world of web development, efficient data handling and presentation are crucial. As applications scale and datasets grow, presenting large amounts of information in a user-friendly way becomes a significant challenge. This is where pagination, a powerful technique for dividing content into separate pages, becomes crucial. In particular, for FastAPI, a modern, fast (high-performance) web framework for creating APIs in Python, effective implementation of pagination is not only beneficial, but often essential for optimal performance and user experience.
This article will explain the process of implementing pagination in FastAPI. We will embark on a journey to explore the importance of pagination, its impact on the user experience and how it improves the performance of API responses. In addition, we will dive into the practical aspects, providing a step-by-step guide to implementing pagination in a FastAPI application. Whether you're a beginner looking to learn the basics or an experienced developer looking to refresh your skills, this guide promises to equip you with the knowledge and tools you need to master pagination in FastAPI.
Join me as we develop the pagination layers in FastAPI, illustrating its implementation with clear code examples, best practices and performance considerations. By the end of this article, you will not only understand the importance of pagination, but you will also be able to effectively implement it in your FastAPI.
What is Pagination and Why is it Important?
Pagination is a method used in web development to divide large sets of data or content across multiple pages within a web application or an API. This technique is a cornerstone in creating efficient, scalable, and user-friendly digital experiences.
Imagine trying to find a specific item in an enormous, unsorted pile. It's overwhelming, isn't it? That's the user experience when a web application attempts to display an excessive amount of data at once. Pagination elegantly solves this by breaking the data into smaller, more manageable sections, making navigation and comprehension a breeze for the user. It's like organizing that pile into neatly stacked shelves where everything is easily accessible.
The importance of pagination extends beyond just user convenience. Consider the performance aspect: loading vast amounts of data in one go can strain both the server and the user’s device, leading to slower response times and a frustrating user experience. Pagination mitigates this by only requesting and loading a fraction of the data at a time, significantly speeding up the process and conserving server resources.
For applications dealing with data analysis or reporting, pagination is a godsend. It allows users to focus on digestible chunks of data, making it easier to process and understand the information presented. In the realm of search engine optimization (SEO), particularly for content-rich platforms like blogs or e-commerce sites, pagination helps search engines index pages more efficiently, potentially improving a site’s search rankings.
Furthermore, pagination has become a standardized practice in web development, supported by most modern frameworks and libraries. This standardization not only simplifies the implementation process but also makes it a universally understood concept among developers.
In essence, pagination is more than just a design element; it’s an integral component of modern web design and development. It plays a crucial role in enhancing usability, boosting performance, and ensuring efficient data management, especially in applications handling extensive datasets.
Environment Setup and FastAPI Installation
Python Installation
FastAPI is built on Python, so the first step is to ensure you have Python
installed. FastAPI requires Python 3.7 or higher. You can verify your Python
version by running python:
Copied!--version
or
Copied!python3 --version
in your terminal. If you don’t have Python installed, download it from the official Python website.
Creating Virtual Environment
It’s good practice to use a virtual environment for your Python projects. This isolates your project’s dependencies from your global Python installation. You can create a virtual environment in your project directory by running:
Copied!python3 -m venv venv
Where second venv it is name of your virtual environment. Activate on
Unoix/macOS it with source:
Copied!venv/bin/activate
or on Windows:
Copied!venv\Scripts\activate
FastAPI Installation
With your virtual environment active, install FastAPI using pip, Python’s package manager. Simply run:
Copied!pip install fastapi
This command fetches FastAPI and installs it in your environment.
FastAPI is an ASGI web framework and requires an ASGI server to run. Uvicorn is a lightning-fast ASGI server that works exceptionally well with FastAPI. Install it using command:
Copied!pip install uvicorn
Verifying the Installation
To ensure FastAPI and Uvicorn are correctly installed, you can create a simple test file. In a new Python file, write a FastAPI application:
Copied!from fastapi import FastAPI app = FastAPI() @app.get("/") def home(): return {"Hello": "World"}
Run this app with uvicorn:
Copied!uvicorn main:app --reload
Replace main with the name of your Python file where you store your code. Open
your browser and navigate to http://127.0.0.1:8000. You should see a response
{"Hello": "World"}
Database setup
Integrating a database into your FastAPI application is a critical step that influences how you manage and serve your paginated data. For our purposes, we're opting for an SQLite database for its simplicity and ease of integration into various environments.
Using encode/databases for Database Connection
To communicate with the SQLite database, we will use the encode/databases library, which offers asynchronous support and is well-suited for use with FastAPI. This library provides a simple and efficient way to perform database operations asynchronously, which is crucial for maintaining performance as our application scales.
Why Not an ORM? While ORMs like SQLAlchemy are powerful and widely used in the industry, I personally prefer the simplicity and immediacy that coding/database offers. I find it often simplifies the development process, especially for applications that require precise control over database queries and a lightweight interaction layer.
I plan to write a detailed article in the future presenting specific reasons for choosing coding/databases over an ORM approach. This upcoming article will provide some insights into the trade-offs and benefits from a practical point of view. It's important to note that this is a matter of preference, and you should use the tools that best fit your project's needs. If you are more comfortable with an ORM like SQLAlchemy, you should absolutely use it. Both methods are valid and can effectively support pagination in a FastAPI application.
Now we need to install two libraries:
Copied!pip install sqlalchemy
Copied!pip install databases[aiosqlite]
Preparing base endpoints
Designing pydantic model
FastAPI uses Pydantic models for data validation and schema definition, which
simplifies data handling and entry. Here's a quick look at the basic Pydantic
model representing Movie, which will be our representing model in this
tutorial:
Copied!from pydantic import BaseModel class Movie(BaseModel): id: int title: str description: str director: str year: int
This movie model defines a movie object structure with fields for id,
title, description, director and year. Each field is typed, specifying
the expected data type that Pydantic enforces. When a request is sent to our
FastAPI application, it will use this model to validate the incoming data,
making sure all fields are present and have the correct type.
Pydantic's use of Python's type annotation not only helps with validation, but also improves editor support by making it easier to catch errors early in the development process. The Movie model serves as a contract for the API, ensuring that the data conforms to the specified structure.
Preparing database
In our FastAPI application, we start by setting up a SQLite database, a
lightweight and easy-to-use database ideal for small to medium applications.
Using SQLAlchemy, we define the structure of our Movie table, which will store
the movie data.
The schema for our Movie table includes columns for id, title,
description, director and year. Here, SQLAlchemy's Column and data type
declarations come into play, creating a clear, well-defined table structure in
our SQLite database.
We initialize the database using SQLAlchemy's create_engine method, specifying
our DATABASE_URL, which points to the SQLite database file. Importantly, for
SQLite, we include the connect_args={"check_same_thread": False} argument to
ensure compatibility with FastAPI's asynchronous nature.
Finally, we use the encode/databases library to create a Database instance.
This library provides asynchronous support for database operations, aligning
perfectly with FastAPI's async capabilities. It allows us to perform database
operations like querying, inserting, and updating data asynchronously, which is
key for maintaining high performance in our paginated API.
For the purpose of this guide, we directly include the DATABASE_URL in the
code. However, it's crucial to remember that in a production environment, you
should never hardcode sensitive data like database URLs directly in your source
code. Instead, store such sensitive information in an .env file and add this
file to your .gitignore. This practice keeps your sensitive data secure and
away from your version control system.
Copied!import databases import sqlalchemy DATABASE_URL = "sqlite:///data.db" metadata = sqlalchemy.MetaData() movie_table = sqlalchemy.Table( "movies", metadata, sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True), sqlalchemy.Column("title", sqlalchemy.String), sqlalchemy.Column("description", sqlalchemy.String), sqlalchemy.Column("director", sqlalchemy.String), sqlalchemy.Column("year", sqlalchemy.Integer), ) engine = sqlalchemy.create_engine( DATABASE_URL, connect_args={"check_same_thread": False} ) metadata.create_all(engine) database = databases.Database(DATABASE_URL, force_rollback=False)
Creating API Endpoints for load data
This is what the json file looks like with the data we will use as our movie
data in the database. The file can be found in the repository linked at the end
of the article:
Copied![ { "id": 1, "title": "The Great Adventure", "description": "An epic journey through uncharted territories.", "director": "Jane Smith", "year": 2020 }, { "id": 2, "title": "City Lights", "description": "A heartfelt story set in a bustling metropolis.", "director": "John Doe", "year": 2018 }, { "id": 3, "title": "Ocean's Mystery", "description": "Exploring the deep secrets of the ocean.", "director": "Alice Johnson", "year": 2021 }, { "id": 4, "title": "Space Odyssey", "description": "A thrilling space exploration saga.", "director": "Michael Brown", "year": 2022 }, { "id": 5, "title": "Mountain Echoes", "description": "A tale of survival in the mountain wilderness.", "director": "Sarah Lee", "year": 2019 }, { "id": 6, "title": "Lost in Time", "description": "A journey through different eras in history.", "director": "David Wilson", "year": 2020 }, { "id": 7, "title": "Robot Revolution", "description": "A futuristic world dominated by AI.", "director": "Emily Clark", "year": 2023 }, { "id": 8, "title": "Desert Winds", "description": "A story of love and life in the desert.", "director": "Richard Miller", "year": 2018 }, { "id": 9, "title": "Rainforest Chronicles", "description": "Adventures in the lush rainforests.", "director": "Angela White", "year": 2021 }, { "id": 10, "title": "Hidden Treasures", "description": "The hunt for ancient artifacts.", "director": "Daniel Hernandez", "year": 2022 }, { "id": 11, "title": "Winter's Tale", "description": "A magical story set in a winter wonderland.", "director": "Jessica Davis", "year": 2019 }, { "id": 12, "title": "Underground Secrets", "description": "Unveiling the mysteries beneath the city.", "director": "George Martinez", "year": 2020 }, { "id": 13, "title": "Sky High", "description": "A daring adventure in the skies.", "director": "Laura Garcia", "year": 2023 }, { "id": 14, "title": "Digital Dreams", "description": "A virtual reality experience gone awry.", "director": "Brian Robinson", "year": 2018 }, { "id": 15, "title": "Ancient Legends", "description": "Rediscovering myths from ancient civilizations.", "director": "Sophia Anderson", "year": 2024 } ]
In our FastAPI application, we have implemented an endpoint to simplify the
transfer of movie data from a JSON file to our SQLite database. This process
is required to populate our database with the initial data for pagination work.
We start by opening and reading our movies_examples.json file. Then in the
next line we create an insert query. This query is designed to take the data
from the JSON file and map it to our movie_table schema in the database.
Before executing the query, we establish a connection to our database using
database.connect(). We then execute the insert query to transfer all the movie
records from our JSON file into the SQLite database. Once the operation is
complete, we disconnect from the database using database.disconnect().
This endpoint provides a quick and efficient way to populate our database with a dataset, allowing us to focus on implementing and testing pagination in our FastAPI application.
Copied!import json from fastapi import FastAPI from database import database, movie_table app = FastAPI() @app.get("/") def home(): return {"Hello": "World"} @app.post("/movies", response_model=dict, status_code=201) async def load_movies_to_database(): with open("movies_examples.json", "r") as f: data = json.load(f) await database.connect() for movie in data: query = movie_table.select().where(movie_table.c.id == movie["id"]) result = await database.fetch_one(query) if result is None: query = movie_table.insert().values(movie) await database.execute(query) await database.disconnect() return {"status": "Movies loaded successfully"}
To initiate the data population, navigate to the endpoint
http://127.0.0.1:8000/movies in your web browser or API tool. This action
triggers the execution of the script, reading from the JSON file and populating
the database with these movie entries.
The result of this action should look like this:
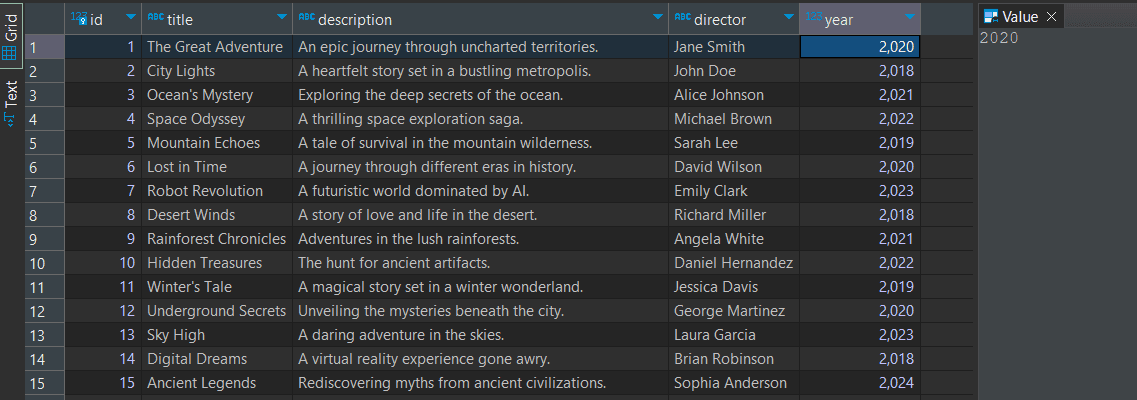
And in the database the data should be in this format:
Building Endpoint for Fetching all movies
The FastAPI application includes a crucial endpoint designed to retrieve movie data from the database. This endpoint is used as a starting point for further improvements, particularly to demonstrate the pagination process.
The endpoint use the Movie Pydantic model to structure its response. This
ensures that the returned data is consistent with a validated schema,
maintaining data integrity and format. Using a simple query, constructed using
SQLAlchemy, retrieve every record from the movie_table. The application then
connects to the database, executes this query, and closes the connection after
fetching the data. This process results in a list of movie records being
returned, serialized into JSON by FastAPI in line with the Movie model.
Copied!import json from typing import List from fastapi import FastAPI from database import database, movie_table from models import Movie app = FastAPI() @app.get("/") def home(): return {"Hello": "World"} @app.post("/movies", response_model=dict, status_code=201) async def load_movies_to_database(): with open("movies_examples.json", "r") as f: data = json.load(f) await database.connect() for movie in data: query = movie_table.select().where(movie_table.c.id == movie["id"]) result = await database.fetch_one(query) if result is None: query = movie_table.insert().values(movie) await database.execute(query) await database.disconnect() return {"status": "Movies loaded successfully"} @app.get("/movie", response_model=List[Movie], status_code=200) async def get_all_movies(): query = movie_table.select() await database.connect() results = await database.fetch_all(query) await database.disconnect() return results
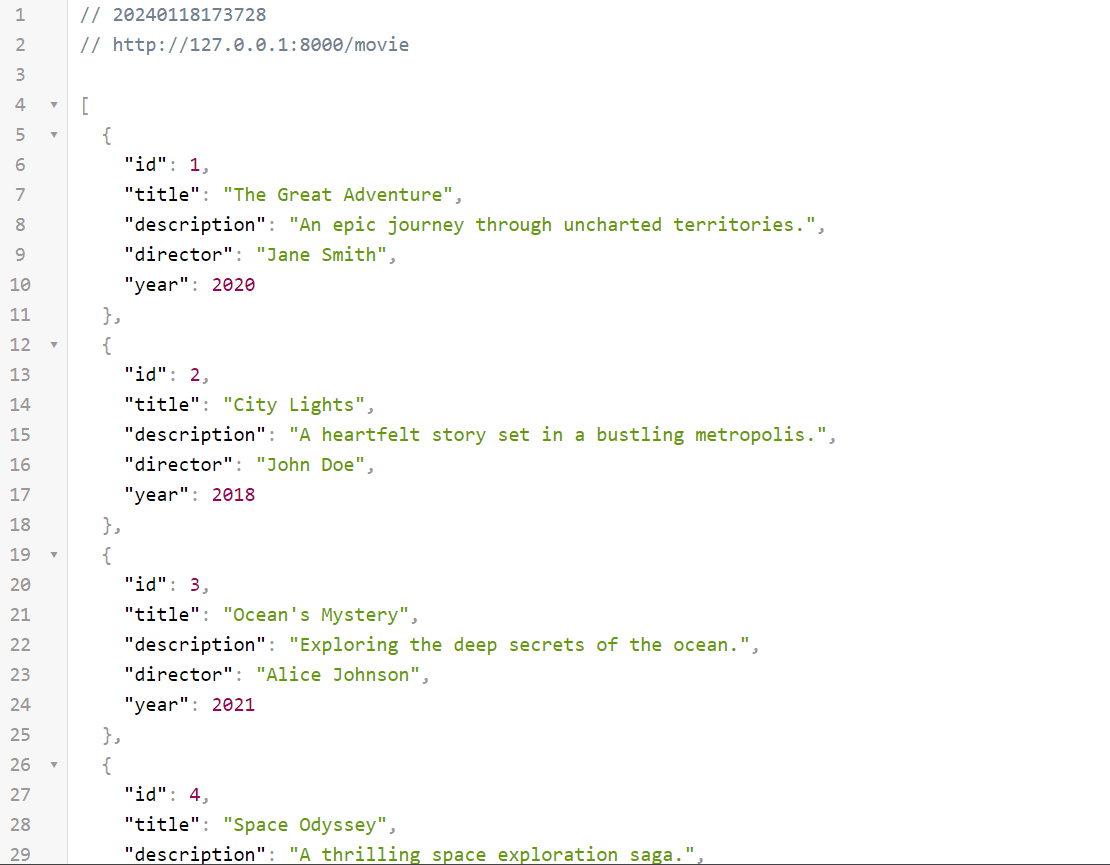
After navigate to endpoint: http://127.0.0.1:8000/movie you should see in your
browser or API tool list of movies with all details.
Limit/offset strategy
Basic implement
As the first pagination strategy for our FastAPI application, we will use the limit/offset method, which is well-suited for small APIs.
The limit/offset pagination strategy involves using two parameters: limit,
which specifies the number of records to return in a single response, and
offset, which indicates the starting point in the dataset from where to begin
fetching records. This approach allows users to navigate through data in
manageable chunks, making it an effective method for small datasets where the
impact on performance is minimal.
The implementation is very straightforward. This get_all_movies endpoint is
configured to accept two query parameters: limit and offset. By default,
limit is set to 10, controlling the number of movie records returned in a
single response, and offset, set to 0 by default, determines the starting
point in the dataset from which to fetch records.
After accessing this endpoint, the application connects to the database and
constructs a query using limit and offset values. The query, formulated
using SQLAlchemy's select, limit and offset methods, retrieves the specified
slice of movie data from the movie_table. After retrieving the results, the
application disconnects from the database and returns a list of movie records,
according to the structure defined by the Movie model.
Copied!import json from typing import List from fastapi import FastAPI, Query from database import database, movie_table from models import Movie app = FastAPI() @app.get("/") def home(): return {"Hello": "World"} @app.post("/movies", response_model=dict, status_code=201) async def load_movies_to_database(): with open("movies_examples.json", "r") as f: data = json.load(f) await database.connect() for movie in data: query = movie_table.select().where(movie_table.c.id == movie["id"]) result = await database.fetch_one(query) if result is None: query = movie_table.insert().values(movie) await database.execute(query) await database.disconnect() return {"status": "Movies loaded successfully"} @app.get("/movie", response_model=List[Movie], status_code=200) async def get_all_movies( limit: int = Query(10, gt=0), offset: int = Query(0, ge=0)): await database.connect() query = movie_table.select().limit(limit).offset(offset) results = await database.fetch_all(query) await database.disconnect() return results
In the documentation at http://127.0.0.1:8000/docs you can play and test a
little bit upgraded endpoint.
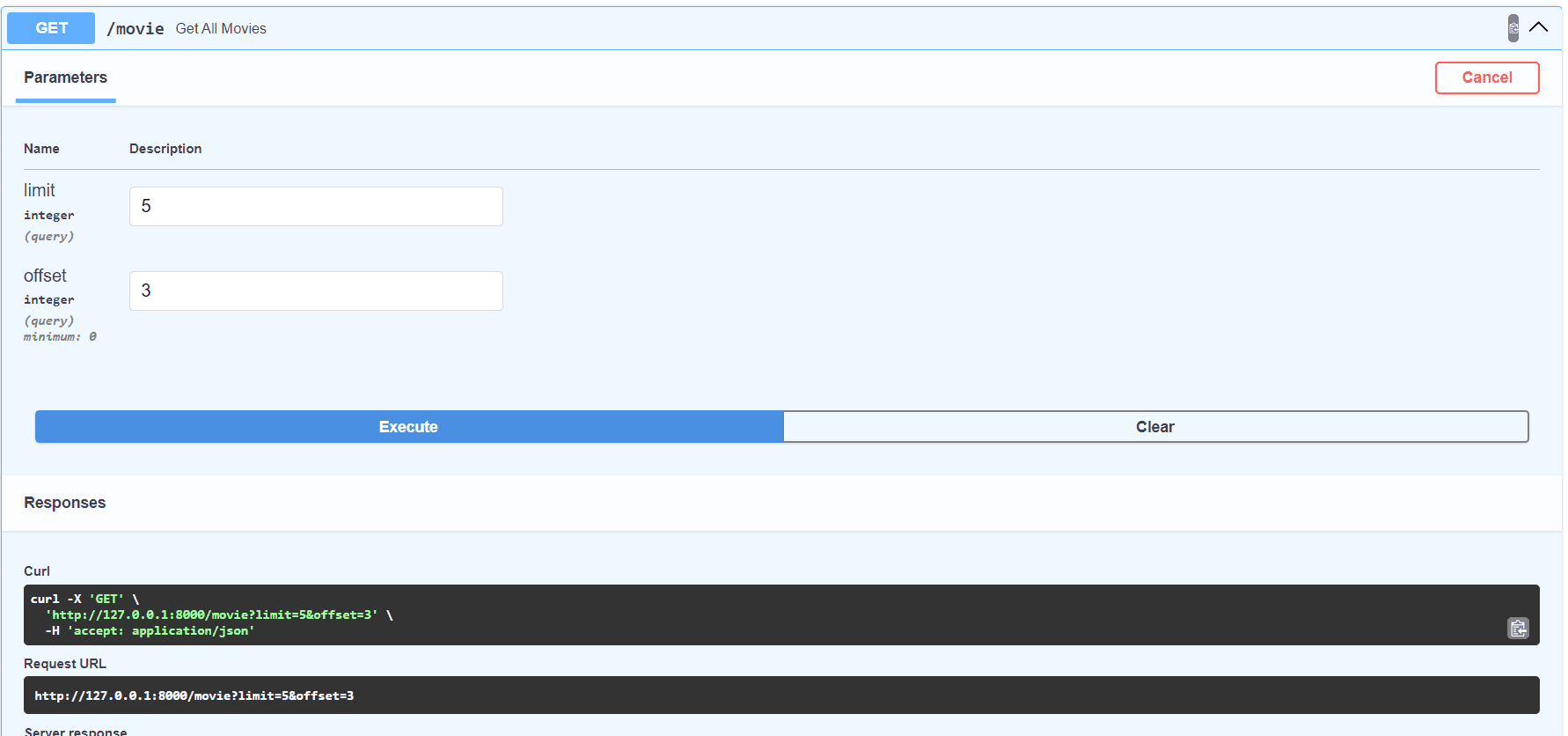
If you want to read more about Query Parameters, which are a really useful
built-in tools in FastAPI, there is link for
a separate section in official documentation.
Expanded pagination
We want to expand our pagination system more so that the user gets a more
friendly and informative way to navigate through movie data. This improvement
introduces a new Pydantic model: PaginatedResponse, which defines what the
response should look like with a more complex pagination system.
It's a generic model that accepts a type variable T, allowing it to be used
with different types of data, such as movies in this case. The model includes
fields for limit (number of items returned), offset (starting index of the
returned items), totalItems (total number of items in the table), nextPageUrl
(url for the next page), prevPageUrl (url for the previous page) and results
(the list of movies returned in the response).
Copied!from typing import Generic, List, Optional, TypeVar from pydantic import BaseModel, Field T = TypeVar("T") class Movie(BaseModel): id: int title: str description: str director: str year: int class PaginatedResponse(BaseModel, Generic[T]): limit: int = Field(description="Number of items returned in the response") offset: int = Field(description="Index of the first item returned in the response") totalItems: int = Field(description="Total number of items in the database") nextPageUrl: Optional[str] = None Field(description="URL to the next page of results if available, otherwise null") prevPageUrl: Optional[str] = None Field( description="URL to the previous page of results if available, otherwise null" ) results: List[T] = Field( description="List of items returned in response according to the provided parameters" )
We move all pagination-related logic to a separate paginate function. It
accepts the current Request, limit, and offset as parameters to determine the
portion of data to fetch and return. On invocation, the function connects to the
database and executes two key queries: one to fetch the paginated list of movies
and another to retrieve the total count of movies in the database. Additionally,
it generates URLs for the next and previous pages, based on the current limit
and offset. These URLs are dynamically created to guide users through the
dataset, adding navigation links to the API response. The function finally
disconnects from the database and returns a PaginatedResponse object, which
includes pagination details (like limit, offset, and totalItems) and the
URLs for navigating to the next and previous pages, along with the actual
paginated results (results).
The /movie endpoint is now adapted to utilize this advanced pagination
function. This GET endpoint, with the PaginatedResponse[Movie] as the response
model, takes in query parameters for limit and offset. When hit, it calls
the paginate function, passing in the current request, limit, and offset
values. This function handles the heavy lifting of pagination and data
retrieval. The response from this endpoint provides clients with not only the
requested movie data but also useful navigation links and total item count,
enhancing the overall API user experience.
Copied!import json import sqlalchemy from fastapi import FastAPI, Query, Request from database import database, movie_table from models import Movie, PaginatedResponse app = FastAPI() @app.get("/") def home(): return {"Hello": "World"} @app.post("/movies", response_model=dict, status_code=201) async def load_movies_to_database(): with open("movies_examples.json", "r") as f: data = json.load(f) await database.connect() for movie in data: query = movie_table.select().where(movie_table.c.id == movie["id"]) result = await database.fetch_one(query) if result is None: query = movie_table.insert().values(movie) await database.execute(query) await database.disconnect() return {"status": "Movies loaded successfully"} async def paginate_l( request: Request, limit: int, offset: int ) -> PaginatedResponse[Movie]: await database.connect() query = movie_table.select().limit(limit).offset(offset) movies = await database.fetch_all(query) count_query = sqlalchemy.select(sqlalchemy.func.count()).select_from(movie_table) total = await database.fetch_one(count_query) base_url = str(request.base_url) next_page = ( f"{base_url}movie?limit={limit}&offset={offset + limit}" if offset + limit < total[0] else None ) prev_page = ( f"{base_url}movie?limit={limit}&offset={max(0, offset - limit)}" if offset - limit >= 0 else None ) await database.disconnect() return { "limit": limit, "offset": offset, "totalItems": total[0], "nextPageUrl": next_page, "prevPageUrl": prev_page, "results": movies, } @app.get("/movie", response_model=PaginatedResponse[Movie], status_code=200) async def get_all_movies( request: Request, limit: int = Query(10, gt=0), offset: int = Query(0, ge=0), ): return await paginate_l(request, limit, offset)
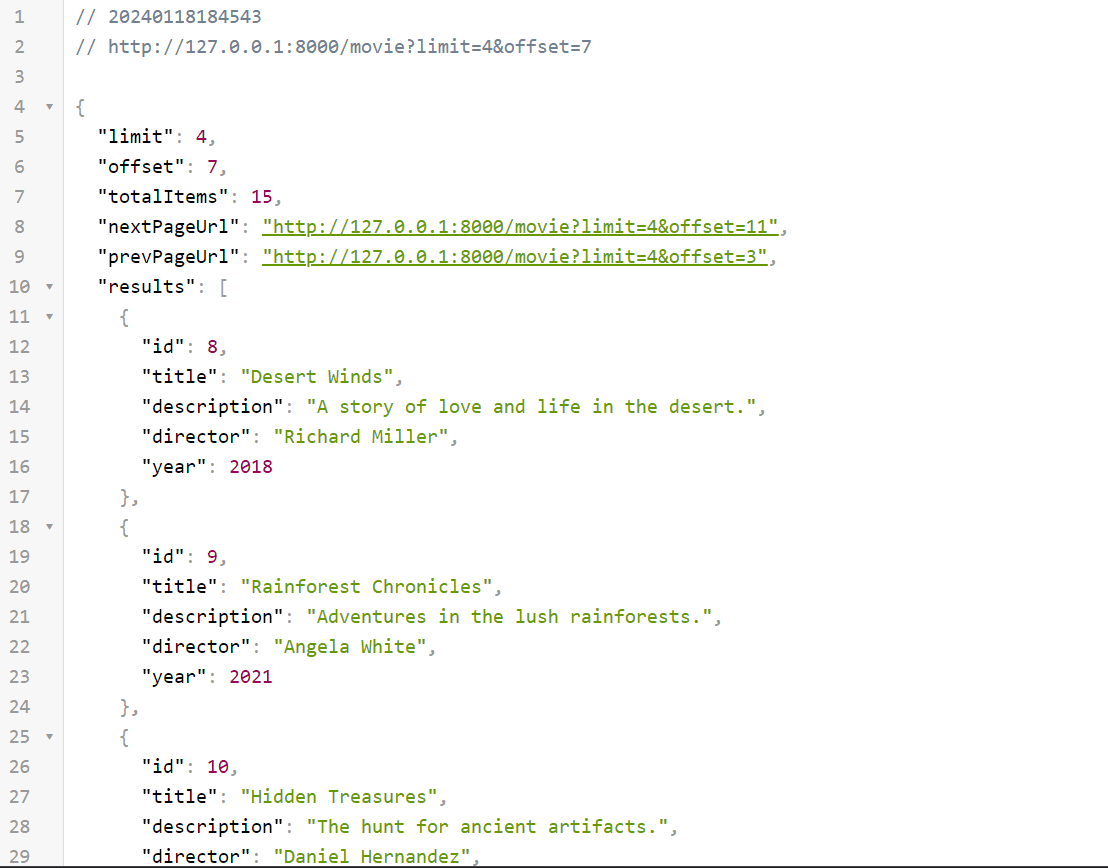
The new response from the /movie endpoint should look like the screenshot
below:
Summary
As we conclude this part of our exploration into pagination with FastAPI, it’s
clear that the limit/offset method provides a robust foundation for navigating
datasets in web applications. We have successfully implemented an advanced
pagination system that not only fetches data efficiently but also enhances user
navigation with dynamically generated URLs for subsequent pages.
This article has grown considerably in length, covering the complexities of
configuring and using limit/offset pagination strategies in FastAPI. Due to the
complex nature of this topic, other pagination methods, such as page/per_page
pagination, require detailed discussion. Therefore, they will be discussed in
the next part of this series, in which we will delve into alternative strategies
that can further optimize data handling and user experience in various
scenarios.
This brings us to the end of this article on implementing limit/offset
pagination in FastAPI. I hope you found it informative and helpful in your
journey with web development. Remember, taking care of yourself is as important
as taking care of your code, so make sure to do both!
Our journey into the intricacies of FastAPI will continue, and other pagination methods await us in the upcoming articles. If you have any questions, uncertainties, or specific topics you'd like to see covered, please don't hesitate to reach out via email. Your queries and insights are invaluable and help shape the content to better suit your learning needs. Looking forward to hearing from you and continuing our exploration in the dynamic world of possibilities! The whole code from the tutorial described here can be found in this repository.